





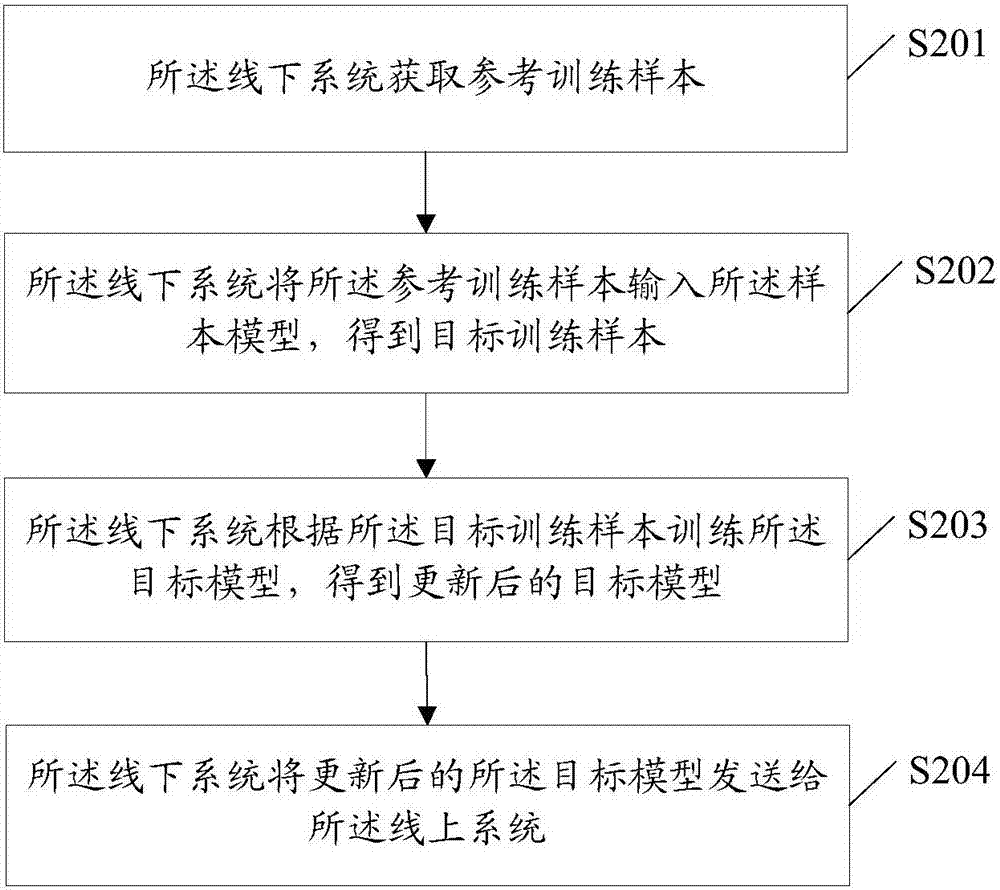
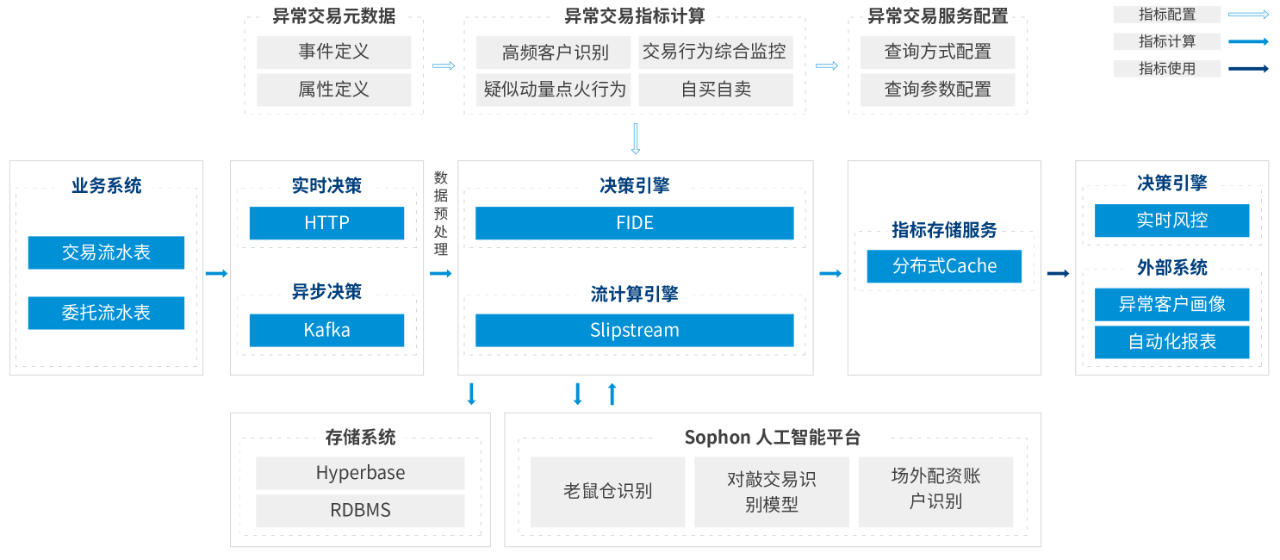
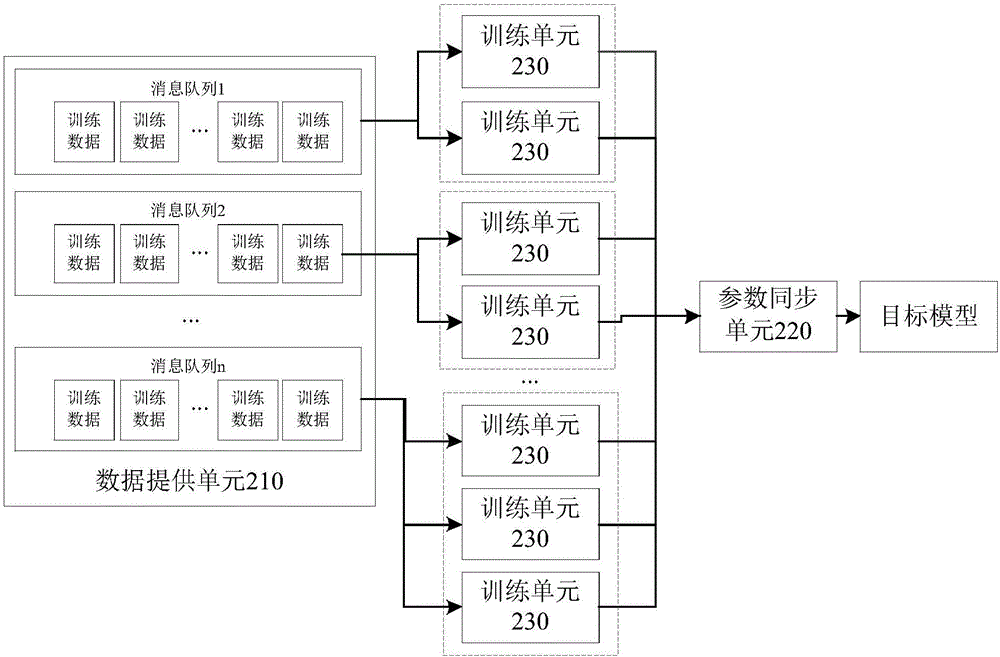
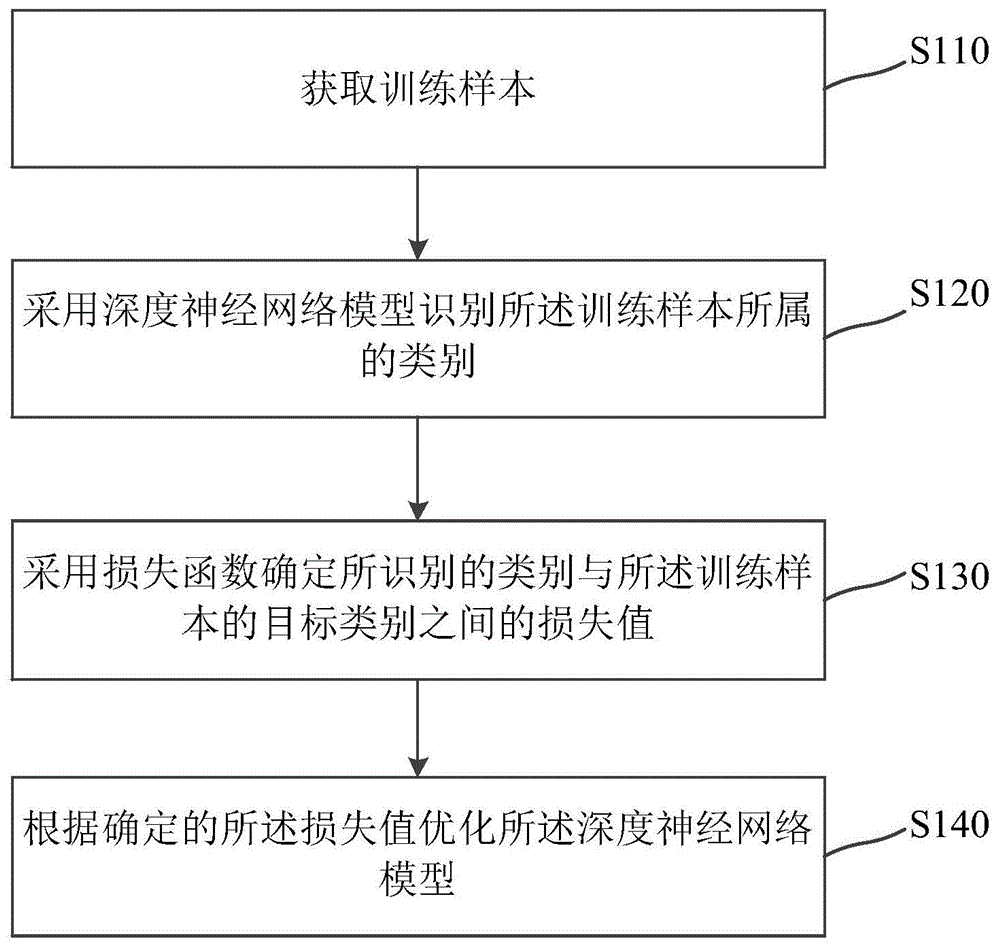
所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2022-07-16 11:07:16来源:网络整理
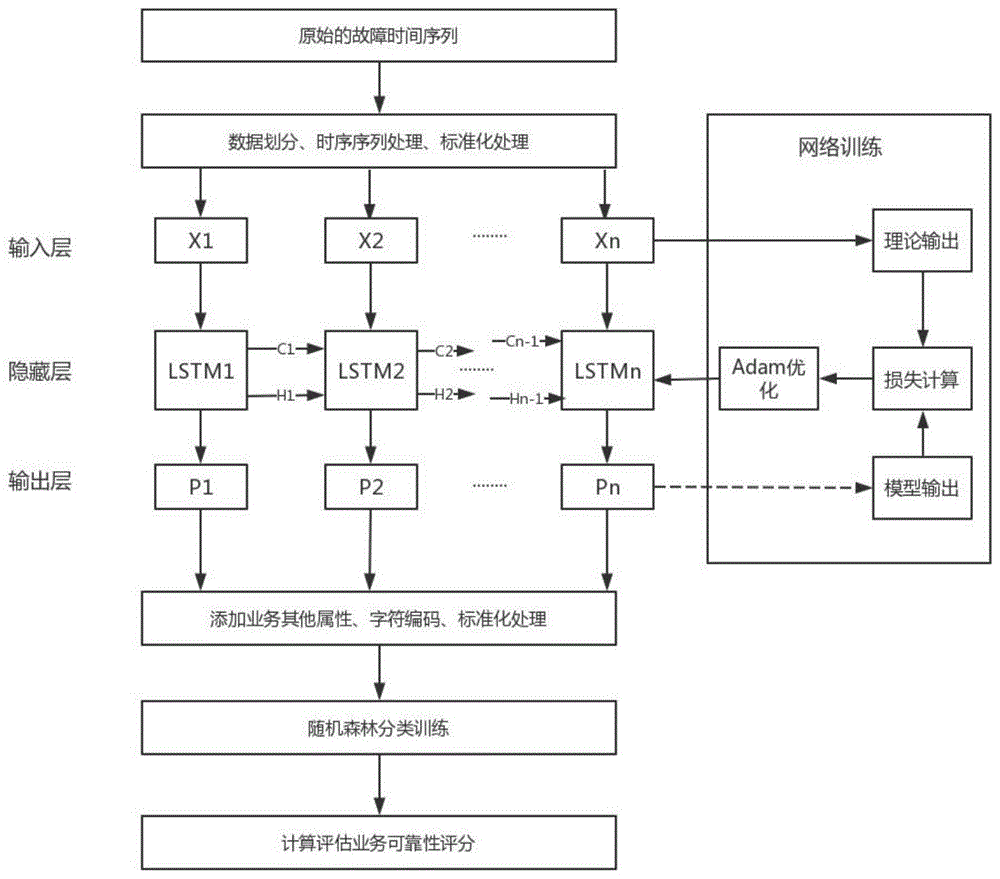
填充序列
为了将此数据输入 RNN,所有输入序列必须具有相同的长度。我们将截断较长的评论,并将评论的最大长度限制为 max_words,并将较短的评论用 0 填充。现在,将 max_words 设置为 500。
from keras.preprocessing import sequence
max_words = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_words)
X_test = sequence.pad_sequences(X_test, maxlen=max_words)
设计用于情感分析的 RNN 模型
我们开始在下面的代码单元中构建模型架构。我们从 Keras 导入了一些您可能需要的层,但您可以随意使用您喜欢的任何其他层/转换。
请记住用户情感分析框架用户情感分析框架,我们的输入是最大长度为 max_words 的单词序列(从技术上讲,序列中的整数是单词 id),而我们的输出是二进制情感标签(0 或 1)。
from keras import Sequential
from keras.layers import Embedding, LSTM, Dense, Dropout
embedding_size=32
model=Sequential()
model.add(Embedding(vocabulary_size, embedding_size,
input_length=max_words))
model.add(LSTM(100))
model.add(Dense(1, activation='sigmoid'))
print(model.summary())
结果如图3所示
图 3
总而言之,我们的模型是一个简单的 RNN 模型,具有 1 个嵌入层、1 个 LSTM 层和 1 个密集层。总共需要训练 213,301 个参数。
训练和评估我们的模型
我们首先需要通过指定要在训练时使用的损失函数和优化器以及我们想要测量的任何评估指标来编译我们的模型。指定适当的参数,包括至少一个指标“准确度”。
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
编译完成后,我们就可以开始训练过程了。我们必须指定两个重要的训练参数 - 批量大小和训练 epoch 数,它们与我们的模型架构一起决定了总训练时间。
培训可能需要一段时间!
batch_size = 64
num_epochs = 3
X_valid, y_valid = X_train[:batch_size], y_train[:batch_size]
X_train2, y_train2 = X_train[batch_size:], y_train[batch_size:]
model.fit(X_train2, y_train2, validation_data=(X_valid, y_valid),
batch_size=batch_size, epochs=num_epochs)
结果如图4所示
图 4
一旦我们训练了模型,就该看看它在未知测试数据上的表现了。
scores[1] 将对应于评估指标 metrics=['accuracy']。
scores =model.evaluate(X_test, y_test, verbose=0)
print('Testaccuracy:', scores[1])
结果:
测试精度:0.86964
总结
我们可以通过多种方式构建模型。我们可以通过试验不同的架构、层和参数来继续试验和提高模型的准确性。如果我们不训练很长时间,我们能做多好?如何防止过拟合?
原发布时间:2018-07-17
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。








图文推荐
2022-07-16 10:02:22

2022-07-15 12:01:25
2022-07-15 09:01:15

2022-07-15 09:01:07
2022-07-14 14:00:49

2022-07-14 13:02:42
热点排行
精彩文章

2022-07-14 11:08:26
2022-07-14 11:07:29
2022-07-14 09:05:41

2022-07-13 14:35:56

2022-07-13 14:34:27
2022-07-13 09:05:24
热门推荐
